Sweet-Home Datasets
(in construction)
The data must be used for research purpose only and are not public access through this site. All participants have given an informed and signed consent about the experiment. The acquisition protocol was submitted to the CNIL. CNIL is the French institution that protects personal data and preserves individual liberties. Consequently, the anonymity of each participant must be preserved.
These databases, devoted to vocal order home automation, are distributed free of charge, for an academic and research use only, in order to be able to compare the results obtained. By downloading these anonymous data, you agree to the following limitations:

This corpus was recorded by the LIG laboratory (Laboratoire d'Informatique de Grenoble, UMR 5217 CNRS/UJF/Grenoble INP/UPMF) thanks to the Sweet-Home project founded by the French National Research Agency (Agence Nationale de la Recherche / ANR-09-VERS-011). The authors would like to thank the participants who accepted to perform the experiments.
This corpus is composed of audio and home automation data acquired in a real smart home with French speakers. This campaign was conducted within the Sweet-Home project aiming at designing a new smart home system based on audio technology. The developed system provides assistance via natural man-machine interaction (voice and tactile command) and security reassurance by detecting distress situations so that the person can manage, from anywhere in the house, her environment at any time in the most natural way possible.
DOMUS smart apartment is part of the experimentation platform of the LIG laboratory and is dedicated for research projects. DOMUS is fully functional and equipped with sensors, such as energy and water consumption, level of hygrometry, temperature, and effectors able to control lighting, shutters, multimedia diffusion, distributed in the kitchen, the bedroom, the office and the bathroom. An observation instrumentation, with cameras, microphones and activity tracking systems, allows to control and supervise experimentations from a control room connected to DOMUS. According to the different research projects, experimentations are conducted with users performing scenarios of daily housework and leisure. Multimodal corpus are produced, synchronized and analyzed in order to evaluate and validate the concerned concept or system. The flat also contains 7 radio microphones set into the ceiling that can be recorded in real-time thanks to a dedicated software StreamHIS able to record simultaneously the audio channels.
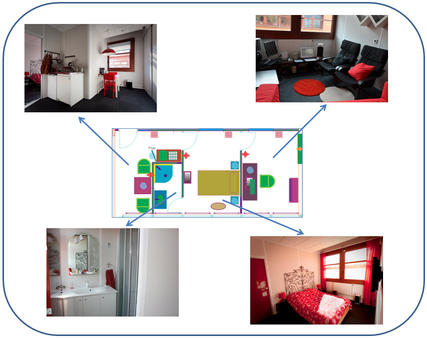
Figure 1: The 35m2 DOMUS flat (kitchen, office, bathroom and bedroom).
The Sweet-Home corpus is made of 3 datasets:
The Multimodal subset was recorded to train models for automatic human activity recognition and location. These two types of information are crucial for context aware decision making in smart home. For instance, a vocal command such as “allume la lumière (turn on the light)” cannot be handled properly without the knowledge of the user’s location. The experiment consisted in following a scenario of activities without condition on the time spent and the manner of achieving them (e.g., having a talk on the phone, having a breakfast, simulating a shower, getting some sleep, cleaning up the flat using the vacuum, etc.). During the experiment, event tracks from the home automation network, audio and video sensors were captured. In total, more than 26 hours of data have been acquired (audio, home automation sensors and videos).
The Home Automation Speech subset was recorded to develop robust automatic recognition of voice commands in a smart home in distant conditions (the microphones were not worn but set in the ceiling). Eight audio channels were recorded to acquire a representative speech corpus composed of utterances of not only home automation orders and distress calls, but also colloquial sentences. The last microphone recorded specifically the noise source for noise cancellation experiments. In order to get more realistic conditions, two types of background noise were considered while the user was speaking: broadcast news radio and a classical music. These were played in the study through two speakers. Note that this configuration poses much more challenges to classical blind source separation techniques than when speech and noise sources are artificially linearly mixed. The participant uttered sentences in different rooms in different conditions. The first condition was without noise, the second one was with the radio turned on in the study and the third one was with classical music played in the study. No instruction was given to the participants about how they should speak or in which direction. Each sentence was manually annotated on the best Signal-to-Noise Ratio (SNR) channel using Transcriber. The third column of Table I shows the details of the record. It was composed, for each speaker, of a text of 285 words for acoustic adaptation (36 minutes for 351 sentences in total for the 23 speakers), and of 240 short sentences (2 hours and 30 minutes per channel in total for the 23 speakers) with a total of 5520 sentences overall. In clean condition, 1076 voice commands and 348 distress calls were uttered while they were respectively 489 and 192 in radio background noise and 412 and 205 with music.
The Interaction subset was recorded during an experiment that consisted in recording users interacting with the Sweet-Home system to evaluate the accuracy of the decision making. The possible voice commands were defined using a simple grammar. Three categories of order were defined: initiate command, stop command and emergency call. Except for the emergency call, every command started with a unique keyword that permits to know whether the person is talking to the smart home or not. The grammar was built after a user study that showed that targeted users would prefer precise short sentences over more natural long sentences. Each participant had to use the grammar to utter vocal orders to open or close blinds, ask about temperature, ask to call his or her relative... The instruction was given to the participants to repeat the order up to 3 times in case of failure. After 3 times, a wizard of Oz technique was used to make the correct decision. 16 participants were asked to perform the scenarios without condition on the duration. In the beginning, the participants were asked to read a text aloud to adapt the acoustic models of the ASR for future experiments. The scenario included 15 vocal orders for each participant but more sentences were uttered because of repetitions.
| The Sweet-Home corpus | |||
|---|---|---|---|
| Attributes | Multimodal subset | Home Automation subset | Interaction subset |
| # Person | 21 | 23 | 16 |
| Age (min-max) | 22-63 | 19-64 | 19-62 |
| Gender | 7F, 14M | 9F, 14M | 7F, 9M |
| Duration per channel | 26h | 3h 6mn | 8h 52mn |
| Speech (#sentences), in French | 1779 | 5520 (2760 noised) | 993 |
| Sounds (#events) | - | - | 3503 |
| Home automation traces | yes | no | yes |
| Noisy | no | yes (vacuum, TV, radio) | no |
| Home automation orders | no | yes | yes |
| Distress call | yes | yes | yes |
| Colloquial call | yes | yes | yes |
| Interaction | no | no | yes |
| Segmented speech | manually | manually | manually and automatically |
| Transcribed speech | yes | yes | yes |
| Transcribed SNR (at sentence level) | yes | yes | yes |
| Transcribed traces | yes | no | no |
| Transcribed sounds | no | no | automatically segmented |
The data of one of the subjects are for the moment made available on this webpage.
The subjects have the following information:
| ID | Age | Gender | Height (m) | Weight (kg) | Native French Speaker? | Regional accent? |
| S01 | 32 | M | 1.83 | 65 | Yes | No |
| S02 | 22 | M | 1.78 | 77 | Yes | No |
| S03 | 56 | F | 1.67 | 56 | Yes | No |
| S04 | 51 | M | 1.78 | 78 | Yes | No |
| S05 | 25 | F | 1.62 | 65 | Yes | No |
| S06 | 23 | M | 1.65 | 60 | Yes | No |
| S07 | 50 | F | 1.6 | 50 | Yes | No |
| S08 | 27 | F | 1.6 | 65 | Yes | No |
| S09 | 36 | M | 1.8 | 65 | Yes | No |
| S10 | 24 | M | 2.1 | 105 | Yes | No |
| S11 | 38 | F | 1.67 | 60 | Yes | No |
| S12 | 42 | M | 1.8 | 80 | Yes | No |
| S13 | 41 | M | 1.77 | 72 | Yes | No |
| S14 | 23 | F | 1.43 | 47 | No | No |
| S15 | 62 | M | 1.65 | 60 | Yes | Yes |
| S16 | 38 | M | 1.76 | 75 | Yes | No |
| S17 | 28 | M | 1.8 | 80 | Yes | No |
| S18 | 46 | M | 1.76 | 80 | Yes | No |
| S19 | 63 | M | 1.7 | 80 | Yes | No |
| S20 | 33 | M | 1.85 | 90 | Yes | No |
| S21 | 48 | F | 1.62 | 59 | Yes | No |
(in construction)
In this section, you will be able to download the dataset for the participant S01.
The video records will not be available for the other participants.
Please read this important notice here before any download: IMPORTANT NOTICE
To retrieve the complete multimodal subset including all the participant's data, you must fill a PDF form and sent it to Michel.Vacher@imag.fr to engage yourself to use this dataset in a correct way. When done, you will receive the link to download the data of the subset.
The data of only two of the subjects are for the moment made available on this webpage.
The subjects have the following information:
| ID | Age | Gender | Height (m) | Weight (kg) | Native French Speaker? | Regional accent? |
| S01 | 56 | M | 1.68 | 67 | Yes | No |
| S02 | 33 | M | 1.80 | 65 | Yes | No |
| S03 | 38 | F | 1.67 | 60 | Yes | No |
| S04 | 26 | M | 1.83 | 75 | Yes | No |
| S05 | 23 | M | 1.84 | 72 | Yes | No |
| S06 | 28 | F | 1.55 | 70 | Yes | No |
| S07 | 30 | M | 1.68 | 55 | Yes | No |
| S08 | 61 | M | 1.69 | 61 | Yes | No |
| S09 | 25 | F | 1.62 | 50 | Yes | No |
| S10 | 19 | M | 1.84 | 85 | Yes | No |
| S11 | 64 | M | 1.70 | 80 | Yes | No |
| S12 | 57 | F | 1.68 | 55 | Yes | No |
| S13 | 46 | F | 1.74 | 69 | Yes | No |
| S14 | 26 | M | 1.74 | 70 | Yes | Yes |
| S15 | 45 | M | 1.77 | 80 | Yes | No |
| S16 | 23 | F | 1.70 | 63 | Yes | No |
| S17 | 26 | M | 1.87 | 100 | Yes | No |
| S18 | 39 | F | 1.70 | 54 | Yes | No |
| S19 | 26 | F | 1.70 | 63 | Yes | Yes |
| S20 | 57 | M | 1.70 | 77 | Yes | No |
| S21 | 29 | M | 1.80 | 80 | Yes | No |
| S22 | 23 | M | 1.83 | 70 | Yes | No |
| S23 | 22 | F | 1.68 | 60 | Yes | No |
| S24 | 25 | F | 1.84 | 71 | Yes | No |
(in construction)
In this section, you will be able to download the dataset for the participants S01 and S02.
Please read this important notice here before any download: IMPORTANT NOTICE
To retrieve the complete home automation subset including all the participant's data, you must fill a PDF form and sent it to Michel.Vacher@imag.fr to engage yourself to use this dataset in a correct way. When done, you will receive the link to download the data of the subset.
| ID | Audio file (.zip) | Speech transcription (Transcriber format.trs) |
| S01 | S01_audio.tar.gz (182M) | speech_S01.trs (6k) |
| S02 | S02_audio.tar.gz (131M) | speech_S02.trs (16k) |
| S03 | × | speech_S03.trs (16k) |
| S04 | × | speech_S04.trs (16k) |
| S05 | × | speech_S05.trs (16k) |
| S06 | × | speech_S06.trs (16k) |
| S07 | × | speech_S07.trs (16k) |
| S08 | × | speech_S08.trs (16k) |
| S09 | × | speech_S09.trs (16k) |
| S10 | × | speech_S10.trs (16k) |
| S11 | × | speech_S11.trs (16k) |
| S12 | × | speech_S12.trs (16k) |
| S13 | × | speech_S13.trs (16k) |
| S14 | × | speech_S14.trs (16k) |
| S15 | × | speech_S15.trs (16k) |
| S16 | × | speech_S16.trs (16k) |
| S17 | × | speech_S17.trs (16k) |
| S18 | × | speech_S18.trs (16k) |
| S19 | × | speech_S19.trs (16k) |
| S20 | × | speech_S20.trs (16k) |
| S21 | × | speech_S21.trs (16k) |
| S22 | × | speech_S22.trs (16k) |
| S23 | × | speech_S23.trs (16k) |
| S24 | × | speech_S24.trs (16k) |
Please read this important notice here before any download: IMPORTANT NOTICE
(in construction)